Congratulations, Dr. Sitchinava!
This morning I took part in the (successful) thesis defense of Nodari Sitchinava, a student of Mike Goodrich here.
Nodari's thesis work is a theoretical reaction to some developments in the practical world of computer design. According to Moore's law, the number of circuit components that can be placed on a single chip has been doubling every two years and is expected to continue doing so for some time. For many years, this exponential progress also meant that individual CPUs were increasing in speed exponentially, although not at the same rate, but in recent years it has been increasingly impractical for a single CPU to take advantage of the glut of transistors available on a chip. Instead, manufacturers have resorted to multi-core systems: my laptop is a dual-core machine (it has two CPUs), it is quite common to see quad-core systems, and we hear rumors that much higher numbers of CPUs are coming. But how can we program such machines to use all that power effectively? For the small numbers of CPUs that we have so far, it works well enough to use conventional multithreading approaches, but as the number of CPUs grows the need for more sophisticated algorithms to feed them grows as well. And as past work on parallel algorithms has shown, an essential part of the difficulty in developing such algorithms is communications: past models of parallelism such as the PRAM that assumed that communications was free and looked only at the number of parallel instructions have not done well at turning theory into practice.
Nodari's approach to this problem is to define and develop algorithms for the parallel external memory model (depicted below in a figure stolen from the thesis), a model of computation that combines features of the PRAM and the external memory model from sequential computing. In this model, one has a collection of independent processors, with individual caches of memory and a large shared memory. Data can be transferred in blocks between main memory and the caches, with a requirement that no two processors write the same block at the same time (in the old PRAM terminology, this is a CREW access pattern). The goal is to minimize the total number of block transfers needed to complete an algorithm, and (secondarily) to maximize the number of processors that can be effectively used. With a single processor, this becomes the standard external memory model, and with a block size and cache size of one this becomes the standard PRAM, so lower bounds from both models can be transferred directly, and many algorithmic ideas from the other models continue to work here.
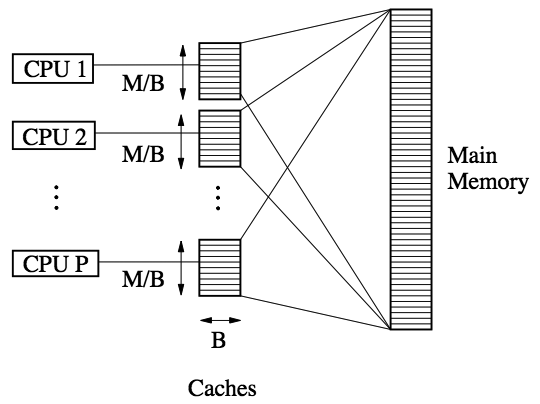
The main part of Nodari's thesis concerns algorithms for this new model. Part of the difficulty is that even standard problems such as list ranking that are easy on a PRAM become hard on the PEM: there are lower bounds coming from the external memory model that list ranking is no easier than sorting. The issue is that one can't simply follow a chain of pointers one step at a time, because each step might require transferring a whole block of data only to read a single word from it. For this reason, most graph algorithms are similarly difficult. But Nodari describes optimally efficient algorithms for basic subroutines such as list ranking and sorting, graph problems such as connectivity testing and minimum spanning trees, and geometry problems such as convex hull construction.
The PEM model should be distinguished from a different model of multi-core algorithms that take advantage of the massively parallel systems already available in off-the-shelf graphics hardware. These systems have the same multi-core CPU power that is incorporated into the PEM model, but as I said above, communications rather than CPU is the bottleneck. In the graphics systems, the communications model involves handling data as large streams rather than via shared memory. These graphics systems can perform many tasks very efficiently but it is not as easy to deal with pointer-based data structures as are needed in graph algorithms using them, and I think there's plenty of good theory still to be done in that direction as well.
Nodari will be leaving Irvine in about a week, to start a postdoc with Lars Arge in the MADALGO group in Aarhus, Denmark. Congratulations, Nodari!
Comments:
2009-11-01T03:45:48Z
I completely missed this, but congratulations to Nodari!