Different entropies
Suppose we have a random variable \( X \), which may take on \( n \) distinct values \( 0, 1, 2, \dots n-1 \) with probability \( p_i \) for taking value \( i \). If we don't care about the ordering of the values, we may as well assume they are sorted in descending order by probability: \( p_i \gt p_{i+1} \). The Shannon entropy of this system, \[ E = -\sum p_i \log_2 p_i, \] gives a lower bound on the expected path length of a binary code for \( X \), that is, a binary tree having \( X \)'s values at its leaves (in any order).
But there is another formula we can use that defines an entropy based on ranks:
\[ R = \sum p_i \log_2 (i+1). \]It turns out that \( E \gt R \gt E/2 \). The first inequality follows trivially from the fact that \( 1/(i+1) \gt p_i \); the second, from the entropy lower bound on path length together with the existence of a binary code with expected path length bounded by \( 2R \):
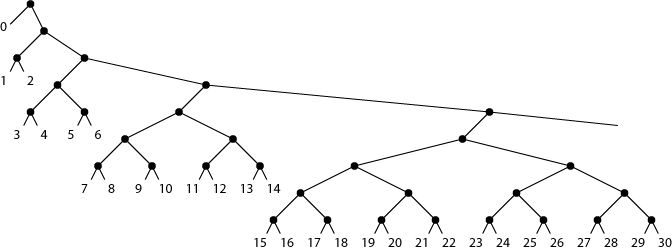
The same inequalities also hold with the same proof if one takes floors of the logs in the definition of \( R \). I imagine that this must all be well known to the statistical physicists: the rank entropy must have some kind of name, and the inequality between rank entropy and Shannon entropy must be in the literature somewhere and probably also has a name. But, not being a statistical physicist myself, I'm having trouble finding any of this literature. Google searches for combinations of "rank", "entropy", and "inequality" lead to lots of interesting material but not (yet) anything describing this. Is anyone else familiar with this kind of rank entropy, and, if so, where do I find out about it?
ETA: Why I care about this.
Comments:
2006-03-02T23:22:16Z
David:
I've send email, and called you on the phone, and couldn't get through either way (your voice mail gives an error message). This is about your paper "Quasiconvex Analysis of Backtracking Algorithms" for TALG. Send me email if you get this.
Alex Lopez-Ortiz
alopez-oATuwaterlooATca
2006-03-02T23:50:55Z
Cool picture! I'm assuming you made it. What tool did you use?
Julian
2006-03-03T00:02:47Z
Thanks... Adobe Illustrator.
2006-03-03T08:33:57Z
Your entropy is strictly related to the average lenght of "one-to-one codes" (in case one uses the floor of the logs in your definition of R). There are two kind of such a codes, the ones more strictly related to your quantity R are those in which the "empty word" is allowed in the encoding. There are several papers in IEEE Transactions on Information Theory about that. General one-to-one codes were introduced in the paper S. K. Leung-Yan-Cheong and T. M. Cover, "Some equivalences between Shannon entropy and Kolmogorov complexity," IEEE Trans. Info. Theory, vol. IT-24, pp. 331 - 338, May 1978. The last paper I am aware of is C. Blundo and R. de Prisco, "New bounds on the expected length of one-to-one codes," IEEE Trans. Info. Theory, vol. IT-42, pp. 246 - 250, January 1996. Hope it helps.
2006-03-03T21:38:39Z
The definition with the floor is more relevant to me, actually, so these references look very helpful. Thanks!
2006-03-04T22:52:32Z
Your tree makes me think of the working set structure in: John Iacono. Alternatives to splay trees with $O(\log n)$ worst-case access times. In Symposium on Discrete Algorithms (SODA), pages 516-522, 2001. -- Stefan.
2006-03-06T09:16:13Z
Do you know the following papers?
Peter Elias, Interval and recency rank source coding: two on-line adaptive variable-length schemes, IEEE Transactions on Information Theory, v.33 n.1, p.3-10, January 2, 1987.
Jon Louis Bentley , Daniel D. Sleator , Robert E. Tarjan , Victor K. Wei, A locally adaptive data compression scheme, Communications of the ACM, v.29 n.4, p.320-330, April 1986.
2006-03-06T16:38:39Z
I didn't know them before, but after seeing your comment I looked them up — thanks! Both look relevant, as they use something resembling the rank coding described above as part of broader coding schemes, and prove bounds on it, though it seems their bounds aren't quite the simple one above that I'm interested in (I'm more interested in the entropy inequality itself, in that form, and less in applications of it to coding techniques or more accurate but more complex inequalities for R). Elias does point to an earlier paper by Wyner as the source of the easy direction of the inequality.